
摘要: AI 領域蓬勃發展,今年深度學習、強化學習、自然語言學習等皆有所成長與突破。本文整理了 2018 年 AI 領域的重大進展,同時也給出了相關的資源位址,以便大家使用、查詢。

2018 ,仍是 AI 領域激動人心的一年。
這一年成為 NLP(Natural Language Processing,自然語言處理)研究的分水嶺,各種突破接連不斷; CV(Computer Vision,電腦視覺)領域同樣精采紛呈,與四年前相比 GAN(Generative Adversarial Network,生成對抗網路)生成的假臉逼真到讓人不敢相信;新工具、新框架的出現,也讓這個領域的明天特別讓人期待。
近日, Analytics Vidhya 發佈了一份 2018 人工智慧技術總結與 2019 趨勢預測報告,原文作者 PRANAV DAR 。量子位在保留這個報告架構的基礎上,對內容進行了重新編輯和補充。
這份報告總結和整理了全年主要 AI 技術領域的重大進展,同時也給出了相關的資源位址,以便大家更好的使用、查詢。
報告共涉及了五個主要部分:
自然語言處理(NLP)
電腦視覺(CV)
工具和庫
強化學習(RL)
AI 道德
下面,我們就逐一來盤點和展望。
自然語言處理(NLP)
2018 年在 NLP 歷史上的特殊地位,已經毋庸置疑。
這份報告認為,這一年正是 NLP 的分水嶺。 2018 年裡, NLP 領域的突破接連不斷: ULMFiT 、 ELMo 、最近大熱的 BERT。
遷移學習成了 NLP 進展的重要推動力。從一個預訓練模型開始,不斷去適應新的數據,帶來了無盡的潛力,甚至有「NLP 領域的 ImageNet 時代已經到來」一說。
■ ULMFiT
這個縮寫,代表「通用語言模型的微調」,出自 ACL 2018 論文: Universal Language Model Fine-tuning for Text Classification。

正是這篇論文,打響了今年 NLP 遷移學習狂歡的第一槍。
論文兩名作者一是 Fast.ai 創始人 Jeremy Howard ,在遷移學習上經驗豐富;一是自然語言處理方向的博士生 Sebastian Ruder ,他的 NLP 博客幾乎所有同行都在讀。
兩個人的專長綜合起來,就有了 ULMFiT 。想要搞定一項 NLP 任務,不再需要從 0 開始訓練模型,拿來 ULMFiT ,用少量數據微調一下,它就可以在新任務上實現更好的性能。
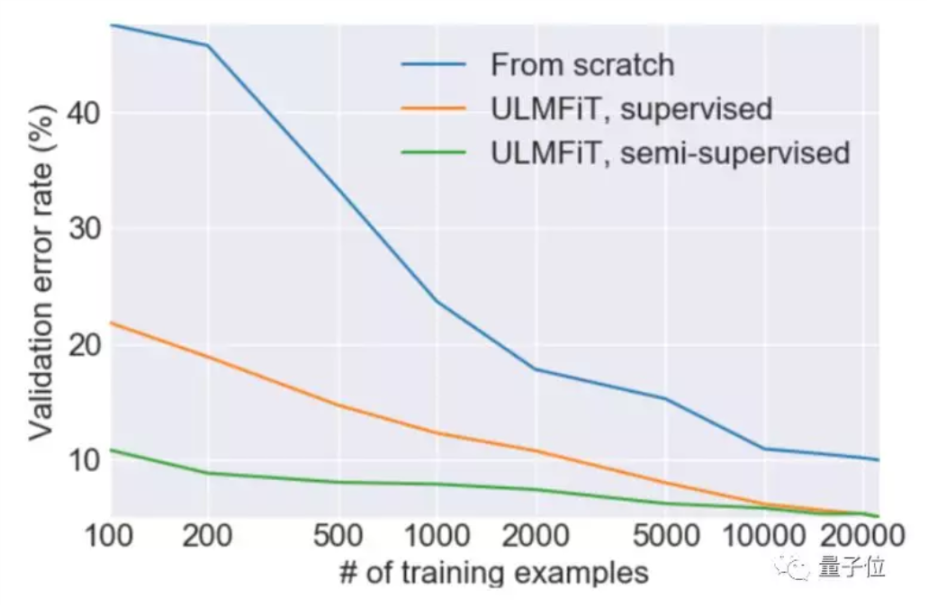
他們的方法,在六項文本分類任務上超越了之前最先進的模型。
詳細的說明可以讀他們的 論文
Fast.ai 網站 上放出了訓練腳本、模型
■ ELMo
這個名字,當然不是指《芝麻街》裡那個角色,而是「語言模型的詞嵌入」,出自艾倫人工智慧研究院和華盛頓大學的論文 Deep contextualized word representations , NLP 頂會 NAACL HLT 2018 的優秀論文之一。

ELMo 用語言模型(language model)來獲取詞嵌入,同時也把詞語所處句、段的語境考慮進來。
這種語境化的詞語表示,能夠體現一個詞在語法語義用法上的複雜特徵,也能體現它在不同語境下如何變化。
當然, ELMo 也在試驗中展示出了強大功效。把 ELMo 用到已有的 NLP 模型上,能夠帶來各種任務上的性能提升。比如在機器問答數據集 SQuAD 上,用 ELMo 能讓此前最厲害的模型成績在提高 4.7 個百分點。
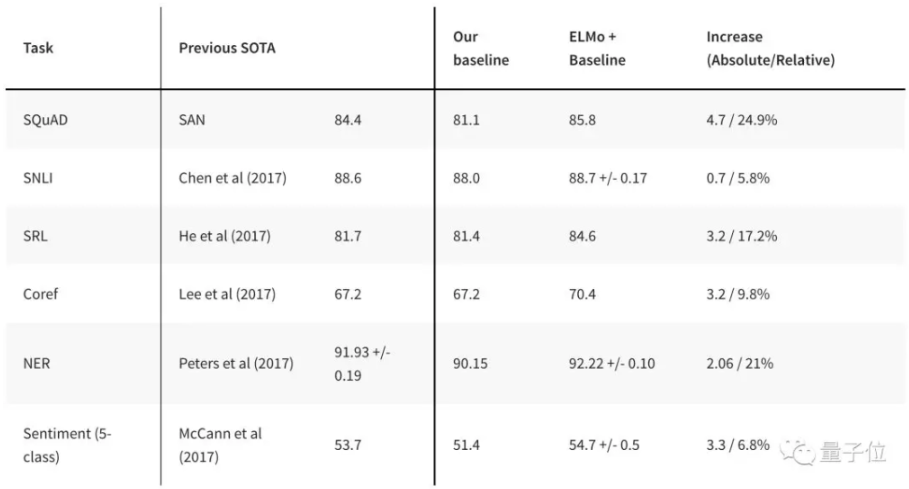
這裡 有 ELMo 的更多介紹和資源
■ BERT
說 BERT 是 2018 年最火的 NLP 模型,一點也不為過,它甚至被稱為 NLP 新時代的開端。

它由 Google 推出,全稱是 Bidirectional Encoder Representations from Transformers ,意思是來自 Transformer 的雙向編碼器表示,也是一種預訓練語言表示的方法。
從性能上來看,沒有哪個模型能與 BERT 一戰。它在 11 項 NLP 任務上都取得了最頂尖成績,到現在, SQuAD 2.0 前 10 名只有一個不是 BERT 變體:
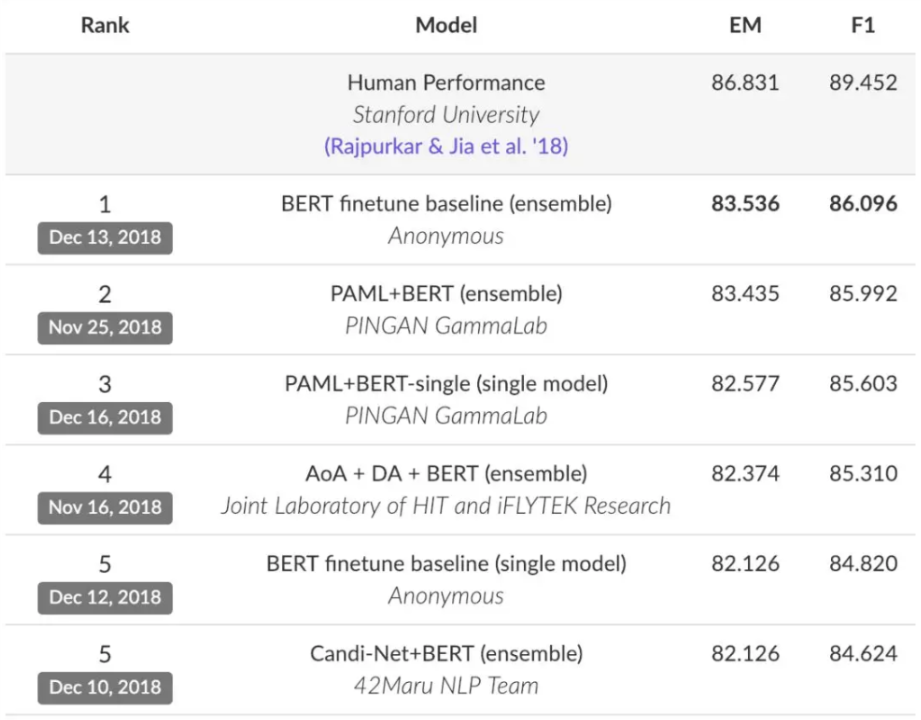

如果你還沒有讀過 BERT 的 論文 ,真的應該在 2018 年結束前補完這一課。
另外,Google 官方開源了 訓練代碼和預訓練模型 。
如果你是 PyTorch 黨,也不怕。這裡還有官方推薦的 PyTorch 重實現和轉換腳本 。
■ PyText
BERT 之後, NLP 圈在 2018 年還能收穫什麼驚喜?答案是,一款新工具。
就在上週末, Facebook 開源了自家工程師們一直在用的 NLP 建模框架 PyText 。這個框架,每天要為 Facebook 旗下各種應用處理超過 10 億次 NLP 任務,是一個工業級的工具包。
(Facebook 開源新 NLP 框 架:簡化部署流程,大規模應用也 OK)
PyText 基於 PyTorch ,能夠加速從研究到應用的進度,從模型的研究到完整實施只需要幾天時間。框架裡還包含了一些預訓練模型,可以直接拿來處理文本分類、序列標註等任務。
想試試?開源地址 在此
■ Duplex
如果前面這些研究對你來說都太抽象的話, Duplex 則是 NLP 進展的最生動例證。

名字有點陌生?不過這個產品你一定聽說過,它就是 Google 在 2018 年 I/O 開發者大會上展示的「打電話 AI」。
它能主動打電話給美髮店、餐館預約服務,全程流暢交流,簡直以假亂真。 Google 董事長 John Hennessy 後來稱之為「非凡的突破」,還說:「在預約領域,這個 AI 已經通過了圖靈測試」。
Duplex 在多輪對話中表現出的理解能力、合成語音的自然程度,都是 NLP 目前水平的體現。
■ 2019 年展望
NLP 在 2019 年會怎麼樣?我們借用一下 ULMFiT 作者 Sebastian Ruder 的展望:
預訓練語言模型嵌入將無處不在:不用預訓練模型,從頭開始訓練達到頂尖水平的模型,將十分罕見。
能編碼專業信息的預訓練表示將會出現,這是語言模型嵌入的一種補充。到時候,我們就能根據任務需要,把不同類型的預訓練表示結合起來。
在多語言應用、跨語言模型上,將有更多研究。特別是在跨語言詞嵌入的基礎上,深度預訓練跨語言表示將會出現。
電腦視覺(CV)
今年,無論是圖象還是影片方向都有大量新研究問世,有三大研究曾在 CV 圈掀起了集體波瀾。
■ BigGAN
今年 9 月,當搭載 BigGAN 的雙盲評審中的 ICLR 2019 論文現身,行家們就沸騰了:簡直看不出這是 GAN 自己生成的。
在電腦圖像研究史上, BigGAN 的效果比前人進步了一大截。比如在 ImageNet 上進行 128 × 128 分辨率的訓練後,它的 Inception Score(IS)得分 166.3 ,是之前最佳得分 52.52 的 3 倍。
除了搞定 128 × 128 小圖之外, BigGAN 還能直接在 256 × 256 、 512 × 512 的 ImageNet 數據上訓練,生成更讓人信服的樣本。

在論文中研究人員揭秘, BigGAN 的驚人效果背後,真的付出了金錢的代價,最多要用 512 個 TPU 訓練,費用可達 11 萬美元,合人民幣 76 萬元(約新台幣 330 萬元)。
不止是模型參數多,訓練規模也是有 GAN 以來最大的。它的參數是前人的 2 – 4 倍,批次大小是前人的 8 倍。
■ Fast.ai 18 分鐘訓練整個 ImageNet
在完整的 ImageNet 上訓練一個模型需要多久?各大公司不斷下血本刷新著記錄。
不過,也有不那麼燒計算資源的平民版。
今年 8 月,在線深度學習課程 Fast.ai 的創始人 Jeremy Howard 和自己的學生,用租來的亞馬遜 AWS 的雲端運算資源, 18 分鐘在 ImageNet 上將圖像分類模型訓練到了 93% 的準確率。
前前後後, Fast.ai 團隊只用了 16 個 AWS 雲實例,每個實例搭載 8 塊英偉達 V100 GPU ,結果比 Google 用 TPU Pod 在斯坦福 DAWNBench 測試上達到的速度還要快 40%。
這樣拔群的成績,成本價只需要 40 美元(約 1200 元新台幣), Fast.ai 在博客中將其稱作人人可實現。
■ vid2vid 技術
今年 8 月,英偉達和 MIT 的研究團隊高出一個超逼真高解析影片生成 AI。
只要一幅動態的語義地圖,就可獲得和真實世界幾乎一模一樣的影片。換句話說,只要把你心中的場景勾勒出來,無需實拍,電影級的影片就可以自動 P 出來:

除了街景,人臉也可生成:
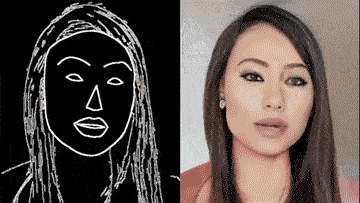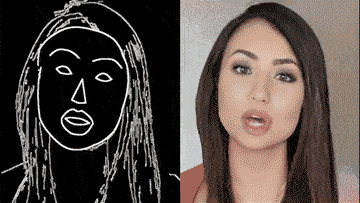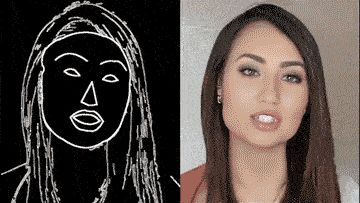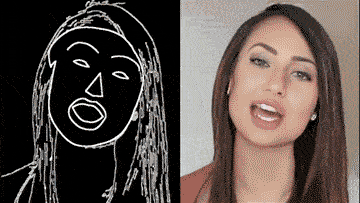
這背後的 vid2vid 技術,是一種在生成對抗性學習框架下的新方法:精心設計的生成器和鑒別器架構,再加上時空對抗目標。
這種方法可以在分割蒙版、素描草圖、人體姿勢等多種輸入格式上,實現高分辨率、逼真、時間相干的影片效果。
好消息, vid2vid 現已被英偉達開源。
■ 2019 趨勢展望
Analytics Vidhya 預計,明年在電腦視覺領域,對現有方法的改進和增強的研究可能多於創造新方法。
在美國,政府對無人機的限令可能會稍微「鬆綁」,開放程度可能增加。而今年火熱的自監督學習明年可能會應用到更多研究中。
Analytics Vidhya 對視覺領域也有一些期待,目前來看,在 CVPR 和 ICML 等國際頂會上公佈最新研究成果,在工業界的應用情況還不樂觀。他希望在 2019 年,能看到更多的研究在實際場景中落地。
Analytics Vidhya 預計,視覺問答(Visual Question Answering,VQA)技術和視覺對話系統可能會在各種實際應用中首次亮相。
工具和框架
哪種工具最好?哪個框架代表了未來?這都是一個個能永遠爭論下去的話題。
沒有異議的是,不管爭辯的結果是什麼,我們都需要掌握和瞭解最新的工具,否則就有可能被行業所拋棄。
今年,機器學習領域的工具和框架仍在快速的發展,下面就是這方面的總結和展望。
■ PyTorch 1.0
根據 10 月 GitHub 發佈的 2018 年度報告, PyTorch 在增長最快的開源項目排行上,名列第二。也是唯一入圍的深度學習框架。
作為谷歌 TensorFlow 最大的「勁敵」, PyTorch 其實是一個新兵, 2017 年 1 月 19 日才正式發佈。 2018 年 5 月, PyTorch 和 Caffe2 整合,成為新一代 PyTorch 1.0 ,競爭力更進一步。
相較而言, PyTorch 速度快而且非常靈活,在 GitHub 上有越來越多的開碼都採用了 PyTorch 框架。可以預見,明年 PyTorch 會更加普及。
至於 PyTorch 和 TensorFlow 怎麼選擇?在我們之前發過的一篇報導裡,不少大老站 PyTorch。
實際上,兩個框架越來越像。前 Google Brain 深度學習研究員 Denny Britz 認為,大多數情況下,選擇哪一個深度學習框架,其實影響沒那麼大。
■ AutoML
很多人將 AutoML 稱為深度學習的新方式,認為它改變了整個系統。有了 AutoML ,我們就不再需要設計複雜的深度學習網絡。
今年 1 月 17 日,谷歌推出 Cloud AutoML 服務,把自家的 AutoML 技術通過雲平台對外發佈,即便你不懂機器學習,也能訓練出一個定製化的機器學習模型。
不過 AutoML 並不是谷歌的專利。過去幾年,很多公司都在涉足這個領域,比方國外有 RapidMiner 、 KNIME 、 DataRobot 和 H2O.ai 等等。
除了這些公司的產品,還有一個開源庫要介紹給大家: Auto Keras
這是一個用於執行 AutoML 任務的開源庫,意在讓更多人即便沒有人工智慧的專家背景,也能搞定機器學習這件事。
這個庫的作者是美國德州農工大學(Texas A&M University)助理教授胡俠和他的兩名博士生:金海峰、 Qingquan Song 。 Auto Keras 直擊谷歌 AutoML 的三大缺陷:
第一,得付錢。
第二,因為在雲端上,還得配置 Docker 容器和 Kubernetes 。
第三,服務商 Google 保證不了你的數據安全和隱私。
■ TensorFlow.js
今年 3 月底的 TensorFlow 開發者會峰會 2018 上, TensorFlow.js 正式發佈。
這是一個面向 JavaScript 開發者的機器學習框架,可以完全在瀏覽器中定義和訓練模型,也能導入離線訓練的 TensorFlow 和 Keras 模型進行預測,還對 WebGL 實現無縫支持。
在瀏覽器中使用 TensorFlow.js 可以擴展更多的應用場景,包括展開交互式的機器學習、所有數據都保存在客戶端的情況等。
實際上,這個新發佈的 TensorFlow.js ,就是基於之前的 deeplearn.js ,只不過被整合進 TensorFlow 之中。
谷歌還給了幾個 TensorFlow.js 的應用案例。比如借用你的攝影機,來玩經典遊戲:吃豆人(Pac-Man)。
■ 2019 趨勢展望
在工具這個主題中,最受關注的就是 AutoML 。因為這是一個真正會改變遊戲規則的核心技術。在此,引用 H2O.ai 的大神 Marios Michailidis(KazAnova)對明年 AutoML 領域的展望:
以智慧可視化、提供洞見等方式,幫助描述和理解數據
為數據集發現、構建、提取更好的特徵
快速構建更強大、更智能的預測模型
通過機器學習可解釋性,彌補黑盒建模帶來的差距
推動這些模型的產生
強化學習(RL)
強化學習還有很長的路要走。
除了偶爾成為頭條新聞之外,目前強化學習領域還缺乏真正的突破。強化學習的研究非常依賴數學,而且還沒有形成真正的產業應用。
希望明年可以看到更多 RL 的實際用例。現在我每個月都會特別關注一下強化學習的進展,以期看到未來可能會有什麼大事發生。
■ OpenAI 的強化學習入門教程
全無機器學習基礎的人類,現在也可以迅速上手強化學習。
11 月初, OpenAI 發佈了強化學習入門教程: Spinning Up 。從一套重要概念,到一系列關鍵演算法實現代碼,再到熱身練習,每一步都以清晰簡明為上,全程站在初學者角度。
團隊表示,目前還沒有一套比較通用的強化學習教材, RL 領域只有一小撮人進得去。這樣的狀態要改變啊!因為強化學習真的很有用。
■ 谷歌的強化學習新框架「多巴胺」
Dopamine(多巴胺),這是谷歌今年 8 月發佈的強化學習開源框架,基於 TensorFlow 。
新框架在設計時就秉承著清晰簡潔的理念,所以代碼相對緊湊,大約是 15 個 Python 文件,基於 Arcade Learning Environment(ALE)基準,整合了 DQN 、 C51 、 Rainbow agent 精簡版和 ICML 2018 上的 Implicit Quantile Networks 。
為了讓研究人員能快速比較自己的想法和已有的方法,該框架提供了 DQN 、 C51 、 Rainbow agent 精簡版和 Implicit Quantile Networks 的玩 ALE 基準下的那 60 個雅達利遊戲的完整訓練數據。
另外,還有一組 Dopamine 的教學 colab 。
Dopamine 谷歌博客
Dopamine github 下載
colabs
遊戲訓練可視化網頁
■ 2019 趨勢展望
DataHack Summit 2018 發言人、 ArxivInsights 創始人 Xander Steenbrugge ,也是一名強化學習專家,以下是來自他的總結和展望。
1、由於輔助學習任務越來越多,增加了稀疏的外在獎勵,樣本的複雜性將繼續提高。在非常稀疏的獎勵環境中,效果非常好。
2、正因如此,直接在物理世界訓練將越來越可行,替代當前大多先在虛擬環境中訓練的方法。我預測 2019 年,會出現第一個只由深度學習訓練,沒有人工參與而且表現出色的機器人 demo 出現。
3、在 DeepMind 把 AlphaGo 的故事延續到生物領域之後(AlphaFold),我相信強化學習將逐步在學術領域外創造實際的商業價值。例如新藥探索、電子晶片架構優化、車輛等等。
4、強化學習會有一個明顯的轉變,以前在訓練數據上測試智能體的行為將不再視為「允許」。泛化指標將成為核心,就像監督學習一樣。
AI 道德
AI 被濫用事故在 2018 年被頻頻爆出: Facebook AI 幫助川普當選美國總統、 Google 與美國軍方聯手開發 AI 武器、微軟為移民和海關執法局(ICE)提供雲端計算和人臉識別服務。
每一次事故都會重新掀起一波對 AI 道德準則的討論高潮,一些矽谷科技公司也再次期間制定了企業 AI 準則。
Analytics Vidhya 認為, AI 道德現在還是一個灰色地帶,目前還沒有所有人可以遵循的框架, 2019 年將有更多企業和政府制定相關條例。
AI 道德規範的制定,現在才剛剛起步。
轉貼自: BuzzOrange
 active
active 
留下你的回應
以訪客張貼回應