

摩根大通報告12個亮點總結:金融領域的機器學習工具有哪些?
金融機構由於面臨激烈的競爭壓力,需要不斷對自身結構和人才資源進行迭代,以適應不斷變化的新情況。隨著微軟前首席科學家鄧力宣布加盟對沖基金巨頭Citadel,我們可以看到金融界已經向計算機科學(特別是機器學習)人才打開了大門。近日,摩根大通發布了一份題為《大數據與人工智能戰略:機器學習和其它投資數據分析方法(Big Data and AI Strategies: Machine Learning and Alternative Data Approach to Investing)》的報告,對機器學習和大數據對金融領域的影響進行了全面的闡述。eFinancialCareers 對這份長達280 頁的報告進行了提煉,得出了12 個重要看點,機器之心對這些看點進行了編譯介紹。

金融領域需要的職位總是隨著時代而改變。在2001 年,互聯網公司分析師非常火爆;2006 年,債務抵押債券設計師風頭正勁;到了2010 年,信貸交易員是最流行的工作;2014 年,職業法規專家成為了主流。到了人工智能興起的2017 年,機器學習和大數據開始影響金融業。如果你有相關專業的背景,金融領域已經向你打開了大門。
摩根大通量化投資和金融衍生品戰略團隊的Marko Kolanovic 和Rajesh T. Krishnamachari 最近剛剛發布了一份在金融服務領域機器學習和大數據最為全面的一份報告。
這份報告名為《大數據和AI 戰略》,副標題是「機器學習和其它投資數據分析方法」,該報告指出,機器學習將會在未來對市場運作至關重要。分析師、投資經理、交易預案和投資總監都需要了解機器學習技術。如果不這樣做,他們就會落伍——像月收益和GDP 數字這樣的常規數據源正在變得與投資策略越來越不相關,因為使用新數據集和方法的投資者可以預測這些數字,並在它們發布前預先做出行動。
這份長達280 頁的報告中包含許多細節,以下是其中的一些重要觀點。
1. 銀行需要聘請優秀的數據科學家,但他們也需要了解市場運作方式
金融專業知識仍是最重要的,摩根大通首先警告銀行和金融公司不要把數據分析技能凌駕於市場知識之上。了解數據和信號背後的經濟學原理要比開發複雜的技術解決方案更重要。
2. 機器最適合在短期和中期做出交易決策
在美國等允許即時交易的市場中,人類已經被排除在高頻交易之外了。在未來,摩根大通認為機器也會成為中期交易的主要玩家:「機器可以快速分析新聞源、推特,處理收益報表,搜索網站,並瞬間完成交易。」這些優勢對於基本面分析師、多空分析師和宏觀投資者非常有幫助。
而對於長線投資而言,人類仍然會保持自己的優勢。「機器在評估結構性變化(市場拐點)和預測方面不會比人更好,這些複雜情況的預測涉及政治家和中央銀行等複雜的人類反應,同時需要了解客戶定位,同時預測大眾情緒,」摩根大通表示。這意味著人類投資者的定位將會發生改變。
3. 金融機構需要大量人力來獲得、提煉和評估數據
在機器學習策略應用之前,數據科學家和量化分析人員需要先獲得併分析數據,這樣才能獲得正確的交易信號和洞見。
摩根大通指出,數據分析具有復雜性。隨著設備數量的增長,今天人們可以獲取的數據集遠遠大於過去。它包含所有從用戶那裡獲取的信息(社交媒體發言、產品評測、搜索記錄等),到商業數據(公司財務數據、交易、信用卡數據等),同時還包括各類傳感器收集到的數據(衛星圖像、交通數據、貨船定位數據等)。這些新形式的數據需要用新的方法進行處理以用於製定交易策略。金融機構也需要評估「Alpha 內容」——生成預期市場可得收益水平的能力。Alpha 內容取決於數據收集的花費,數據處理需要的能力以及數據集的質量。

4. 有很多不同種類的機器學習方法,它們正用於不同目的
機器學習有多種衍生方法,其中包括監督學習、無監督學習、深度學習和強化學習等。
對於金融領域而言,監督學習的目的是建立兩個數據集之間的關係,並使用一個數據集預測另一個數據集;無監督學習的目的是嘗試了解數據的結構,並確定其背後的主要規則;深度學習的目的是使用多層神經網絡來分析事物背後的趨勢;而強化學習則使用算法來探索和找到最有利可圖的交易策略。

5. 監督學習將被用於預測趨勢
在財務背景下,摩根大通認為監督學習算法通過歷史數據,可以找到規律,對未來進行預測。監督學習算法有兩種形式:回歸和分類方式。
回歸形式的監督學習方法嘗試基於輸入變量來預測輸出。例如:如果通貨膨脹速度加快,它可能會判斷下一步市場的走向。
分類方法則與之相反,嘗試將數據識別到已有類別中。
6. 無監督學習將被用於識別大量變量之間的關係(Supervised learning)
在無監督學習中,機器被輸入了一整套資產組合的回報,同時並不知道其中的關聯和獨立變量。在高層次上,無監督學習方法被歸為聚類或因素分析。
聚類分析基於一些相似性概念將數據集分成較小的組。例如:它可以包含歷史數據中高低波動性、經濟上升和下降速率或通貨膨脹的增減。
因素分析旨在識別數據的主要內在規律或確定數據的最佳表示方法。例如:收益曲線的運動可以被解釋為曲線的平行位移、曲線變陡峭或變凸。在復雜資產組合中,因素分析將提煉出數據的主驅動力,如動量、價值、進位、波動或流動性。
7. 深度學習系統將承擔起難以定義但易於執行的任務
深度學習是重現人類大腦智慧的一種方式。摩根大通在報告中認為深度學習特別適合非結構化大數據集的預處理(例如,可應用於分析衛星圖像中的汽車、或新聞稿中的情緒)。深度學習模型可以用虛擬財務數據來預測市場修正概率。
深度學習方法基於神經網絡,而神經網絡是受到人類大腦神經活動的形式而受到啟發的。在網絡中,每個神經元接收來自其他神經元的輸入,併計算這些「神經元」的加權平均值。權重的計算則基於從歷史數據中得來的經驗。
神經網絡的特徵指標,其中包括成本函數、優化器、初始化方案、激活函數、正則化方案
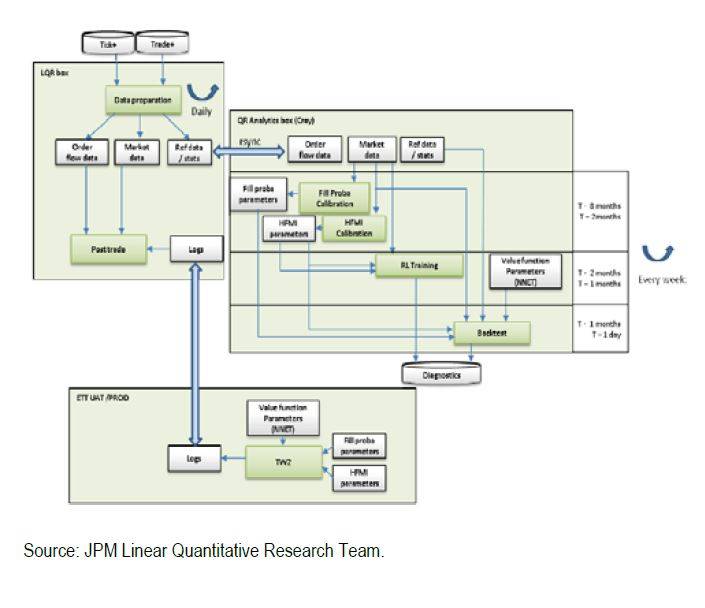
8. 強化學習將被用於行動的選擇,以最大化收益
強化學習的目標是選擇一系列成功的行動以最大化目標(或累積)收益。不同於監督學習(通常只是一步的過程),強化學習模型並不知道每一步的確切行動是什麼。摩根大通的電子交易部門已經開發了一些基於強化學習的算法。下圖顯示了該公司的一些機器學習模型。
9. 你不需要成為一位機器學習專家,但你需要成為一位出色的quant 和出色的程序員
摩根大通說數據科學家應該具備的技能組合基本上和量化研究者差不多。現在有計算機科學、統計學、數學、金融工程學、計量經濟學和自然科學背景的買方和賣方quant 都應該重塑自我。量化交易策略的專業技能將會成為關鍵。Kolanovic 和Krishnamacharc 說:「比起一位IT 專家、矽谷企業家或學者學習如何設計一種可行的交易策略,一個quant 研究者改變數據集的格式/大小並使用更好的統計與機器學習工具可要容易得多。」
摩根大通強調,你並不需要非常詳細地洞悉機器學習的方方面面。大多數機器學習方法都有現成的代碼(比如用R 語言寫的):你只需要應用已有的模型即可。他們建議,開始的時候使用Weka 這樣的基於GUI 的軟件來操作小型數據集。Python 也有Keras 這樣的擴展庫。另外還有TensorFlow 和Theano 這樣的開源機器學習庫。
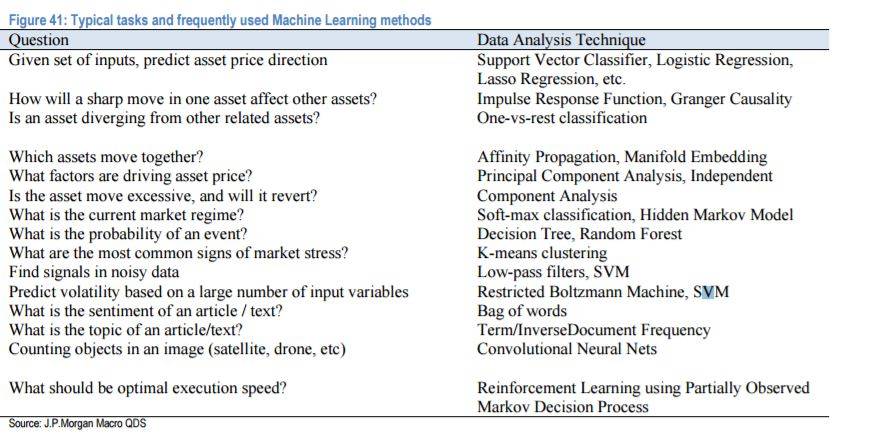
10. 以下為你需要知道的編程語言和數據分析包
如果你只是想要學習一種與機器學習相關的編程語言,摩根大通推薦選擇R 語言,包括下圖中相關的程序包。然而,C++、Python、Java 也如下圖所示有機器學習應用。
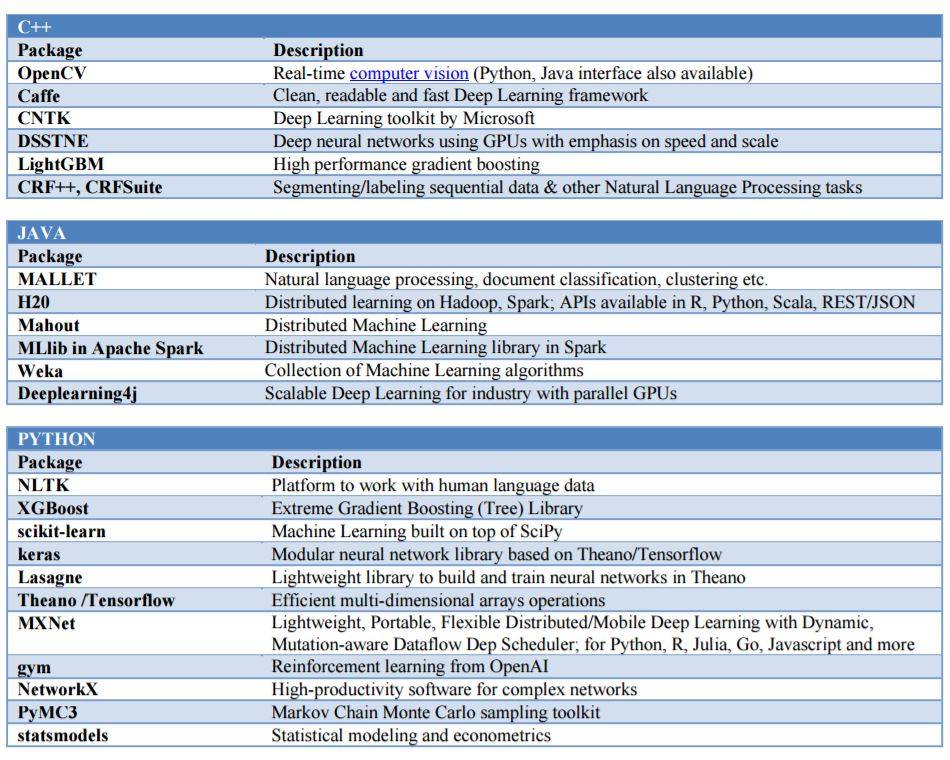


11. 以下為一些流行的Python 語言機器學習代碼示例



12. 支持部門需要理解大數據
最終,摩根大通注意到支持部門也要包含大數據。報告說到,很多雇主與人事經理都無法明確區別「談論人工智能的能力」與「設計可交易策略」的能力,合規團隊需要能夠審查機器學習模型,並保證數據匿名,不包含私人信息。金融領域機器學習時代正在到來。
轉貼自: 搜狐


留下你的回應
以訪客張貼回應